论文笔记|FakeShield:Explainable Image Forgery Detection and Localization via Multi-modal Large Language Models
| 缩写 | 全称 | 翻译 |
|---|---|---|
| IFDL | Image Forgery Detection and Localization | 图像伪造检测与定位 |
1 Introduction
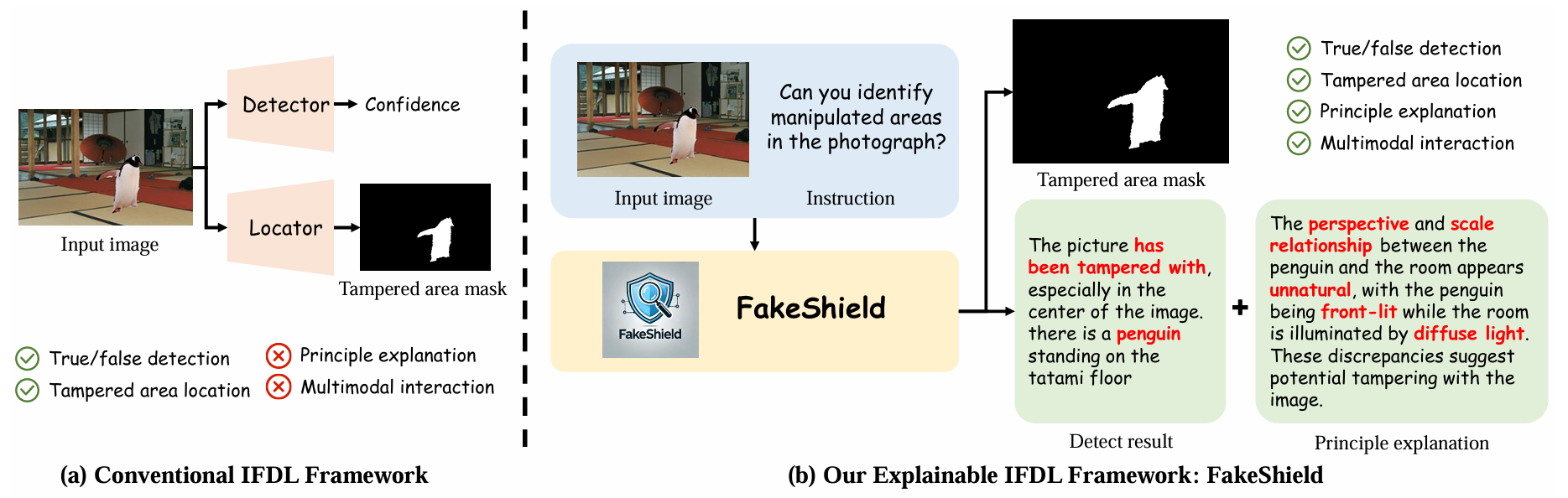
现有图像伪造检测方法的局限性:
- 黑箱特性,检测原理不透明
- 对多样化篡改手段(PS、Deepfake、AIGC-Editing)的泛化能力不足
FakeShield框架能力:
- 评估图像真实性
- 生成篡改区域(可视化)掩码
- 基于像素级(部分)与图像级(全图)的篡改线索提供判断依据
本文贡献:
- 提出FakeShield,基于多模态大语言模型(MLLM)实现可解释图像伪造检测与定位
- 利用GPT-4o为现有的IFDL数据集补充文本信息(构建"图像-掩码-描述"三元组),构建了MMTD-Set数据集
- 开发了“基于域标签的可解释伪造检测模块(DTE-FDM)”,统一模型中识别不同类型的伪造图像
- 性能超越大多数现有的IFDL方法
2 Related Works
- 针对特定操作类型定位、通用篡改定位方法(MVSS-Net, OSN, HiFi-Net, IML-ViT, DiffForensics, etc.)
- LLM & MLLM,利用MLLMs实现通用篡改定位与检测仍属未开发领域
3 Methodology
3.1 Construction of the Proposed MMTD-Set MMTD-Set数据集构建

- 动机:现有的IFDL数据集缺乏文本描述信息
- 挑战:如何将现有IFDL数据集中的视觉篡改信息准确转化为精确的文本描述
- 贡献:
- 利用GPT-4o生成文本描述,并向其提供篡改图像及其对应的掩码,使其能够精确识别篡改位置
- 针对每种篡改类型,我们根据其独特特征设计特定提示,引导GPT-4o聚焦于不同的篡改痕迹,并提供更详细的视觉线索
- 数据收集:
- Au-Scene:真实场景,未篡改,来自:FR, CASIAv2, COCO
- Au-Face: 真实人脸,来自:FFHQ
- PhotoShop Tp-Scene:经过PS篡改的场景图像,来自:FR, CASIAv2
- Deepfake Tp-Face:经过Deepfake篡改的人脸图像,来自:FaceAPP
- AIGC-Editing Tp-Scene:经过AIGC编辑的场景图像
- GPT辅助生成描述
- 输出分析需遵循格式:检测结果、定位描述、判断依据。
- 对于篡改过的图像:
- 输入:篡改图像 + 对应掩码 + 类型专用提示词
- 目标:
- 篡改位置:同时采用绝对坐标(如顶部、右下角)和相对位置(如人群上方、桌面)进行描述
- 篡改内容:详细说明篡改区域内物体的类型、数量、动作及属性,针对不同篡改类型,强调特定视觉线索:
- PS:光照 (Lighting)、常识 (Common Sense)、分辨率 (Resolution)、边缘 (Edge)、复制粘贴 (Copy Paste)、物理定律 (Physical Laws)、透视 (Perspective)、文本 (Text)
- Deepfake:对称性 (Symmetry)、表情 (Expressions)、发型 (Hairstyle)、文本 (Text)、化妆 (Makeup)、配饰 (Accessories)、常识 (Common Sense)、模糊 (Blur)
- AIGC-Editing:纹理 (Texture)、边缘 (Edge)、常识 (Common Sense)、光照 (Lighting)、细节丢失 (Detail Loss)、模糊 (Blur)、解剖错误 (Anatomy Error)、重复 (Repetition)
- 对于真实图像:
- 输入:真实图像 + 类型专用提示
- 目标:引导GPT确认图像真实性,并提供支持判断的视觉线索
3.2 Overall Framework of FakeShield FakeShield整体框架
目标:
- 利用MLLM的文本理解能力和世界知识来分析和判断图像的真实性
- 采用对篡改图像的分析和解读来辅助分割模型精确定位篡改区域

FakeShield模型包含两个关键解耦部分:
- DTE-FDM:Domain Tag-guided Explainable Forgery Detection Module,基于域标签的可解释伪造检测模块
- MFLM:Multi-modal Forgery Localization Module,多模态伪造定位模块
将原始疑似图像$I_{ori}$与指令文本$T_{ins}$(例如“能否识别照片中的篡改区域?”)输入DTE-FDM模块,以预测检测结果及判断依据$O_{det}$。在此过程中,我们采用可学习生成器生成域标签$T_{tag}$,从而规避篡改数据的域冲突问题。
此外,我们将解释结果$O_{det}$与图像$I_{ori}$输入多模态定位模型(MFLM),精准提取篡改区域掩膜$M_{loc}$。为促进跨模态交互实现篡改定位,我们引入篡改理解模块,通过视觉与文本特征对齐增强视觉基础模型对长描述的理解能力。
3.3 Domain Tag-guided Explainable Forgery Detection Module (DTE-FDM) 基于域标签的可解释伪造检测模块
- 动机:篡改方式多样,具有不同特征,单一IFDL方法难以兼顾
- 提出:DTG(Domain Tag Generator,域标签生成器)
- 作用:为每个输入图像生成域标签,指导模型识别不同篡改类型
步骤:
- 原始图像 $I_{ori}$ 输入分类器 $G_{dt}$,生成域标签 $T_{tag}$ 。
- $T_{tag}=G_{dt}(I_{ori})$
- $T_{tag}$: “This is a suspected {data domain}-tampered picture.”
- 原始图像 $I_{ori}$ 经过编码器 $F_{enc}$ 和线性投影层 $F_{proj}$,得到图像Token $T_{img}$。
- $T_{img}=F_{proj}(F_{enc}(I_{ori}))$
- 拼接输入:$T_{ins}+T_{tag}+T_{img}$
- $T_{ins}$:要求模型检测篡改并描述篡改位置的提示词
- 输入LLM,输出结果 $O_{det}=LLM(T_{ins}+T_{tag}+T_{img})$
- $O_{det}=LLM(T_{ins}+T_{tag}+T_{img})$
- $O_{det}$:包含检测结果、篡改区域位置描述、解释检测依据
3.4 Multi-modal Forgery Localization Module (MFLM) 多模态伪造定位模块
- 动机:$O_{det}$提供的“篡改区域位置描述”缺乏精确性和直观性
- 目标:将$O_{det}$转化为精确的二进制掩码
- 提出:TCM(Tampering Comprehension Module,篡改理解模块)
- 作用:将长文本特征与视觉模态对齐,提升SAM(Segment Anything Model)定位伪造区域的精度
步骤:
- 将$T_{img}$与$O_{det}$输入TCM $C_t$,提取最后一层嵌入,通过多层感知器投影层将其转换为$h_{\text{SEG}}$。
- $h_{\text{SEG}}=\text{Extract}(C_t(T_{img},O_{det}))$
- $\text{Extract}$ :提取TCM的最后一层嵌入
- $h_{\text{SEG}}$ 作为 $SAM(S)$ 的中间提示信息,与图像 $I_{ori}$ 的视觉特征 $F_{img}$ 结合,生成最终掩码 $M_{loc}$ 。
- $M_{loc}=S_{dec}(S_{enc}(I_{ori}),h_{\text{SEG}})$
3.5 Training Objectives 训练目标
DTE-FDM训练目标:
$$\ell_{det} = \ell_{ce}(\hat O_{det}, O_{det}) + \lambda \cdot \ell_{ce}(\hat T_{tag}, T_{tag})$$
- $\ell_{ce}$:交叉熵损失函数
- $T_{tag}$:DTG生成的域标签
- $O_{det}$:LLM的预测结果
- $\lambda$:平衡系数
MFLM训练目标:
$$\ell_{loc} = \ell_{ce}(\hat y_{txt}, y_{txt}) + \alpha \cdot \ell_{bce}(\hat M_{loc}, M_{loc}) + \beta \cdot \ell_{dice}(\hat M_{loc}, M_{loc})$$
- $\ell_{bce}$:二进制交叉熵损失
- $\ell_{dice}$:Dice损失
- $y_{txt}$:由TCM生成的包含$\text{
}$标记的高质量提示文本
评论