DL笔记1|神经网络和深度学习
一、深度学习概论
1.1 什么是深度学习
简单来说,深度学习(Deep Learning)就是更复杂的神经网络(Neural Network)
人工神经网络包含:输入层、隐藏层、输出层,每层包含多个神经元,每个神经元包含激活函数
神经网络需要从大量的数据中学习,学习的过程就是调整网络中的参数,使得网络的输出结果与实际结果尽可能接近。
学习的目标是,建立起一个特殊的函数,输入一些数据就能输出想要的结果。
1.2 深度学习的应用
监督学习(Supervised Learning)与无监督学习本质区别就是:训练样本是否已知的输出y
不同的任务通常交给不同的神经网络:
- 分类/回归任务:神经网络(Neural Network, NN)
- 图像识别任务:卷积神经网络(Convolutional Neural Network, CNN)
- 文本/语音等序列任务:循环神经网络(Recurrent Neural Network, RNN)
- 生成任务:生成对抗网络(Generative Adversarial Network, GAN)
机器学习应用于结构化数据(Structured Data)和非结构化数据(Unstructured Data)
- 结构化数据:数据的数据库,意味着每个特征都有清晰的定义,比较容易理解。
- 非结构化数据:通常指的是比较抽象的数据,比如音频、原始音频、图像、文本。
正是因为神经网络,计算机现在能更好地解释非结构化数据,甚至在某些方面优于人类。例如,语音识别,图像识别,自然语音处理等。
1.3 深度学习的优点
深度学习兴起的原因:数据(Data)、计算(Computation)、算法(Algorithm)
深度学习的优点:
- 不需要人工处理设计特征,只需通过神经网络输出结果
- 更适用于难提取特征的任务:图像、语音、自然语言处理
- 能够应对处理更大规模数据
二、神经网络基础
2.1 逻辑回归(Logistic Regression, LR)
逻辑回归是一种用于解决二分类问题的分类算法,给定一个输入x,输出y=1的预测概率 $\hat{y}=P(y=1|x)$
记输入层特征数$n$,参数:
- 输入$x \in R^{n}$,x是一个n维的特征向量
- 权重$w \in R^{n}$,w是一个n维的权重向量
- 标签$y \in {0,1}$,y是一个二分类标签
- 偏置$b \in R$,b是一个标量
- 输出$\hat{y} = \sigma(w^{T}x+b)=\sigma(w_1x_1+w_2x_2+…+w_nx_n+b)$
- 激活函数:Sigmoid函数:$\sigma(t)=\dfrac{1}{1+e^{-t}}$
- t非常大时,s接近1;t非常小时,s接近0;t=0时,s等于0.5
2.2 与梯度下降算法(Gradient Descent)
通过迭代更新参数w和b,使成本函数$J(w,b)$找到最小值(损失函数和成本函数见2.7)
梯度下降算法:函数的梯度(gradient)指出了函数的最陡增长方向。梯度的方向走,函数增长得就越快。那么按梯度的负方向走,函数值自然就降低得最快了

参数更新:
- $w:=w-\alpha \dfrac{\partial J(w,b)}{\partial w}$
- $b:=b-\alpha \dfrac{\partial J(w,b)}{\partial b}$
- $\alpha$:学习率(Learning Rate),控制参数更新的步长,太大会导致震荡,太小会导致收敛速度慢
2.3 逻辑回归的梯度下降
以2维样本 $x_1,x_2$ 为例,参数$w_1,w_2,b$,计算梯度下降
已知:
$$
\begin{split}
&z = w_1x_1+w_2x_2+b \\
&记 a = \hat{y} = \sigma(z) \\
&J(a,y) = -y\log(a)-(1-y)\log(1-a) \\
\end{split}
$$
计算J对z的导数:
$$
\begin{split}
&\frac{\partial J}{\partial a} = \frac{-y}{a}+\frac{1-y}{1-a} \\
&\frac{\partial a}{\partial z} = a(1-a) \\
&dz = \frac{\partial J}{\partial a} \cdot \frac{\partial a}{\partial z} = a-y
\end{split}
$$
这样可以求出总损失相对于$w_1,w_2,b$的导数
- $dw_1 = \frac{\partial J}{\partial z} \cdot \frac{\partial z}{\partial w_1} = x_1(a-y)$
- $dw_2 = \frac{\partial J}{\partial z} \cdot \frac{\partial z}{\partial w_2} = x_2(a-y)$
- $db = \frac{\partial J}{\partial z} \cdot \frac{\partial z}{\partial b} = a-y = dz$
然后更新参数:
- $w_1:=w_1-\alpha dw_1$
- $w_2:=w_2-\alpha dw_1$
- $b:=b-\alpha dw_1$
2.4 前向传播和反向传播
- 前向传播:从前往后计算梯度和损失的过程
- 反向传播:从后往前计算参数的更新梯度值
2.5 向量化/逻辑回归实现
向量化编程的优点:多样本下,向量计算比循环计算快的多,代码更简洁
- 输入层$X$:形状$n \times m$,$n$为特征数,$m$为样本数
- 权重参数$W$:形状$n \times 1$
- 偏置参数$b$:标量
- 输出层$Z$:$Z=W^{T}X+b$,形状$(1,n) \times (n,m) + b = (1,m)$
1 | import numpy as np |
2.6 激活函数(Activation Function)
涉及到网络的优化时候,会有不同的激活函数选择。
有一个问题是神经网络的隐藏层和输出单元用什么激活函数。
在逻辑回归中选用了Sigmoid函数,但有时其他函数的效果会好得多。
大多数结论通过实践得来,没有很好的解释性。
为什么使用非线性的激活函数:使用线性函数,在这一层上的神经元的输出仅仅是输入的线性组合,失去了效果。
$$a^{[1]} = W^{[1]}x+b^{[1]}$$
$$
\begin{align}
b^{[1]} &= W^{[2]}a^{[1]}+b^{[2]} \\
&= W^{[2]}(W^{[1]}x+b^{[1]})+b^{[2]} \\
&= (W^{[2]}W^{[1]})x+(W^{[2]}b^{[1]}+b^{[2]}) \\
&= Wx+b
\end{align}
$$
本节提及的几种常用激活函数:Sigmoid函数、tanH函数、ReLU函数
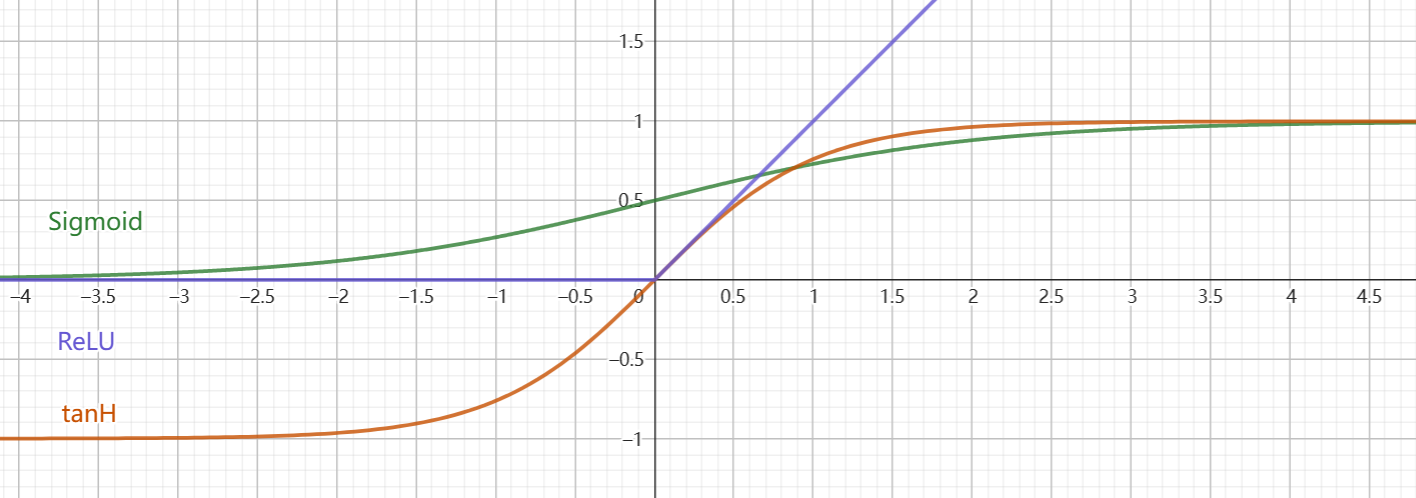
Sigmoid函数
$$
\begin{split}
&\sigma(t)=\dfrac{1}{1+e^{-t}} \\
&\sigma’(t)=\sigma(t)(1-\sigma(t)) \\
&t\in(-\infty,+\infty), \sigma(t)\in(0,1)
\end{split}
$$
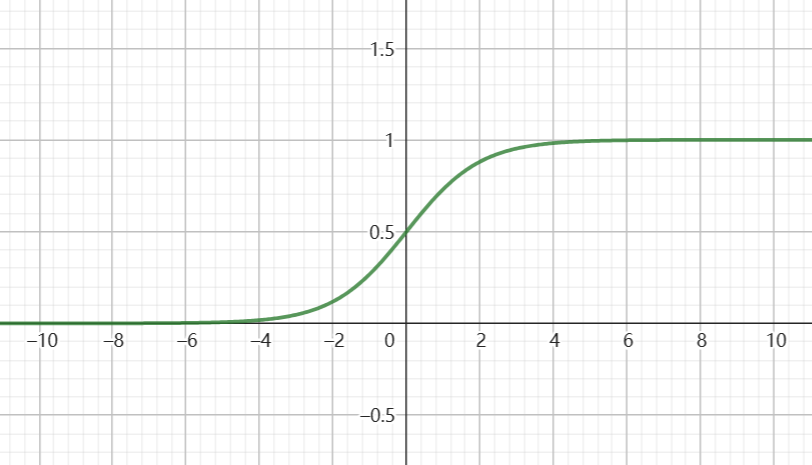
双曲正切函数(Hyperbolic Tangent, tanH)
效果比Sigmoid函数好,因为函数输出在(-1,1)之间,收敛速度更快
存在和Sigmoid函数一样的缺点:当t趋紧无穷,导数的梯度(即函数的斜率)就趋紧于 0,这使得梯度算法的速度会减慢。
$$
\begin{split}
&tanh(t)=\dfrac{e^{t}-e^{-t}}{e^{t}+e^{-t}} \\
&tanh’(t)=1-tanh^2(t)
\end{split}
$$
ReLU函数:修正线性单元(Rectified Linear Unit, ReLU)
当 $t>0$ 时,梯度始终为1,从而提高神经网络基于梯度算法的运算速度,收敛速度远大于Sigmoid和tanH函数
$$
\begin{split}
&f(t)=max(0,t) \\
&f’(t)=\begin{cases}
0 & \text{if } t<0 \\
1 & \text{if } t \geq 0
\end{cases}
\end{split}
$$
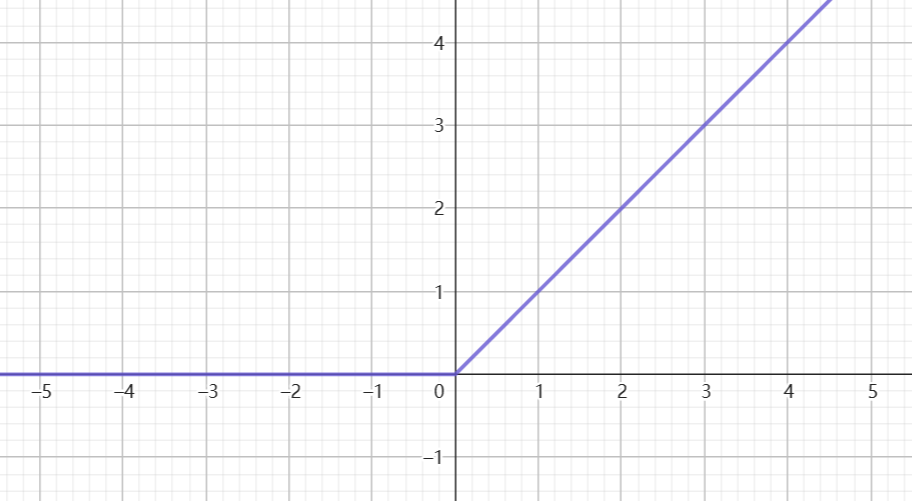
2.7 损失函数(Loss Function)与成本函数(Cost Function)
损失函数用于衡量预测结果与真实值之间的误差。
平方差损失函数:$L(\hat{y},y)=\frac{1}{2}(\hat{y}-y)^2$
- 最简单的损失函数
- 具有多个局部最小值,不适合逻辑回归
对数损失函数:$L(\hat{y},y)=-(y\log(\hat{y})+(1-y)\log(1-\hat{y}))$
- 逻辑回归通常采用的损失函数
- y=1时,损失函数为$-log(\hat{y})$,$\hat{y}$越大,损失越小
- y=0时,损失函数为$log(1-\hat{y})$,$\hat{y}$越小,损失越小
损失函数:衡量了在单个训练样本上的表现
成本函数(Cost Function):$J(w,b)=\dfrac{1}{m}\sum\limits_{i=1}^{m}L(\hat{y}^{(i)},y^{(i)})$
- 所有训练样本的损失平均值
- 衡量在全体训练样本上的表现、参数w和b的效果
三、浅层神经网络
3.1 浅层神经网络
神经网络(Neural Network, NN)是一种模拟人脑神经元工作方式的计算模型,包含输入层、隐藏层、输出层,每层包含多个神经元
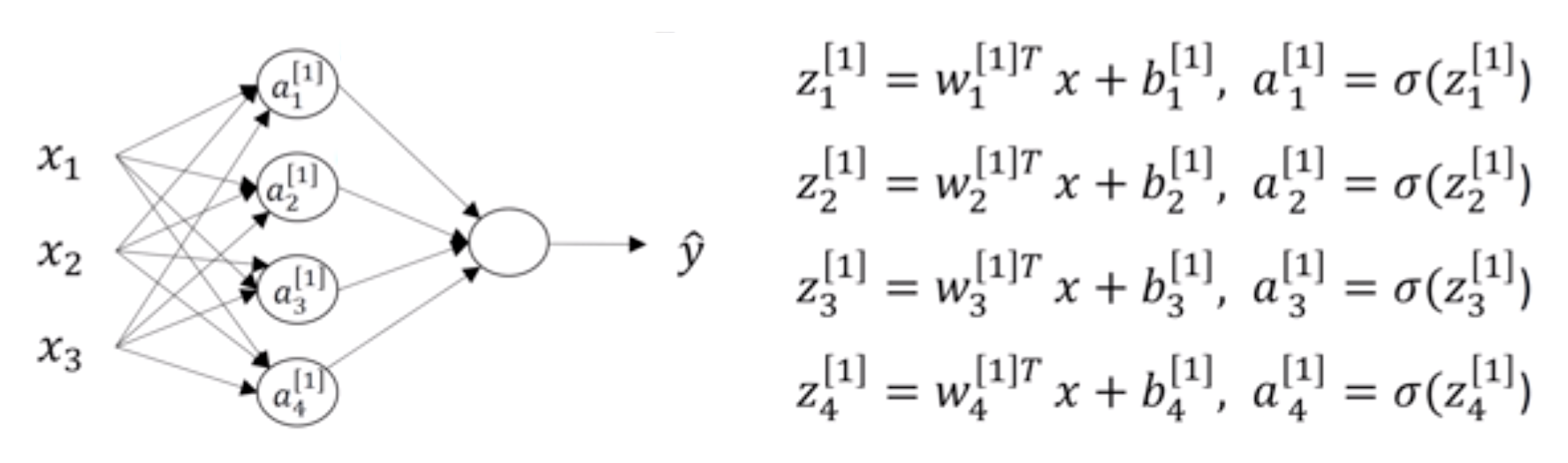
以上图(单隐藏层神经网络)为例,输入层有$n=3$个特征,隐藏层一层,有$4$个神经元。记隐藏层 $[1]$ ,输出层 $[2]$ ,则:
- 输入层:$x \in R^{3}$,$x$是一个$3$维的特征向量
- 形状:(3, m),$m$为样本数
- 隐藏层具有4行3列的权重矩阵$W^{[1]} \in R^{4 \times 3}$,偏置向量$b^{[1]} \in R^{4}$
- 隐藏层的每个神经元$i$具有权重$W^{[1]}{i} \in R^{3}$,偏置$b^{[1]}{i} \in R$
- 形状:输入(3, m) * 权重(4, 3) + 偏置(4, 1) = 输出(4, m)
- 输出层具有1行4列的权重矩阵$W^{[2]} \in R^{1 \times 4}$,偏置$b^{[2]} \in R$
- 形状:输入(4, m) * 权重(1, 4) + 偏置(1, 1) = 输出(1, m)、
总结:第i层的权重矩阵$W^{[i]}$的形状为$(n^{[i]}, n^{[i-1]})$,偏置$b^{[i]}$的形状为$(n^{[i]}, 1)$
3.2 前向传播
$$
\begin{split}
&Z^{[1]} = W^{[1]}X+b^{[1]} \\
&A^{[1]} = tanh(Z^{[1]}) \\
&Z^{[2]} = W^{[2]}A^{[1]}+b^{[2]} \\
&A^{[2]} = \sigma(Z^{[2]})
\end{split}
$$
3.3 反向传播
输出层以Sigmoid函数作为激活函数,根据逻辑回归的梯度下降的推导,可以得到:
$$
\begin{split}
&dZ^{[2]} = A^{[2]}-Y \\
&dW^{[2]} = \dfrac{1}{m}dZ^{[2]}A^{[1]T} \\
&db^{[2]} = \dfrac{1}{m}np.sum(dZ^{[2]}, axis=1)
\end{split}
$$
隐藏层以tanh函数作为激活函数,已知:
$$
\begin{split}
&tanh’(t) = 1-tanh^2(t) \\
&Z^{[1]} = W^{[1]}X+b^{[1]} \\
&A^{[1]} = tanh(Z^{[1]}) \\
&J(A^{[2]},Y) = -Y\log(A^{[2]})-(1-Y)\log(1-A^{[2]})
\end{split}
$$
根据链式求导法则(步骤略),可以得到:
$$
\begin{split}
&dZ^{[1]} = \frac{\partial J}{\partial A^{[2]}} \cdot \frac{\partial A^{[2]}}{\partial Z^{[2]}} \cdot \frac{\partial Z^{[2]}}{\partial A^{[1]}} \cdot \frac{\partial A^{[1]}}{\partial Z^{[1]}} = W^{[2]T}dZ^{[2]} \cdot (1-A^{[1]2}) \\
&dW^{[1]} = \dfrac{1}{m}dZ^{[1]}X^T \\
&db^{[1]} = \dfrac{1}{m}np.sum(dZ^{[1]}, axis=1)
\end{split}
$$
实践:浅层神经网络实现
1 | import numpy as np |
四、深层神经网络
4.1 深层神经网络
为什么需要深层神经网络:
- 神经网络从第一层开始,从原始数据中提取特征
- 下一层将上一层习得的信息组合起来,形成更高级的特征
- 随着层数增多,特征从简单到复杂,学习的能力更强
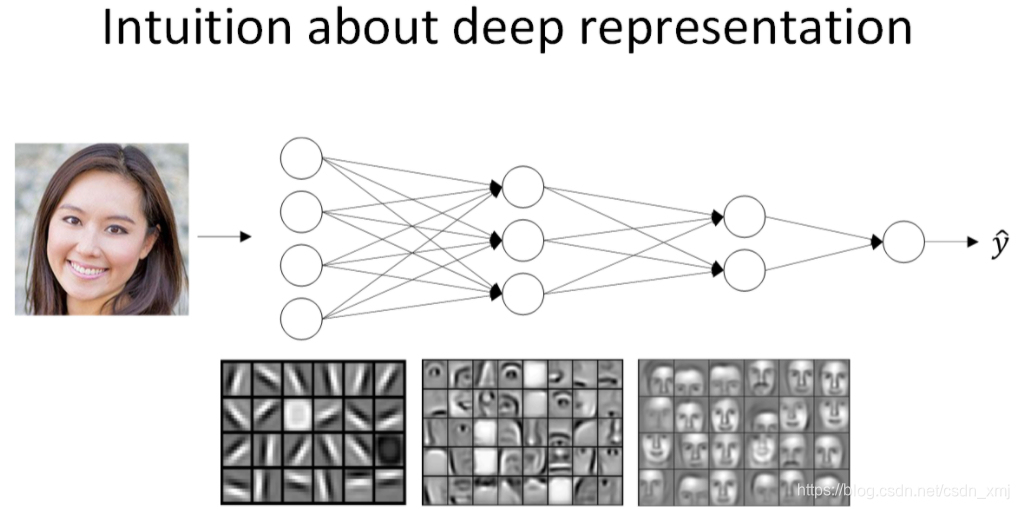
4.2 前向传播
$$
\begin{split}
&x=a^{[0]} \\
&z^{[L]}=W^{[L]}a^{[L-1]}+b^{[L]} \\
&a^{[L]}=g^{[L]}(z^{[L]})
\end{split}
$$
输入$a^{[L-1]}$,输出$a^{[L]}$
4.3 反向传播
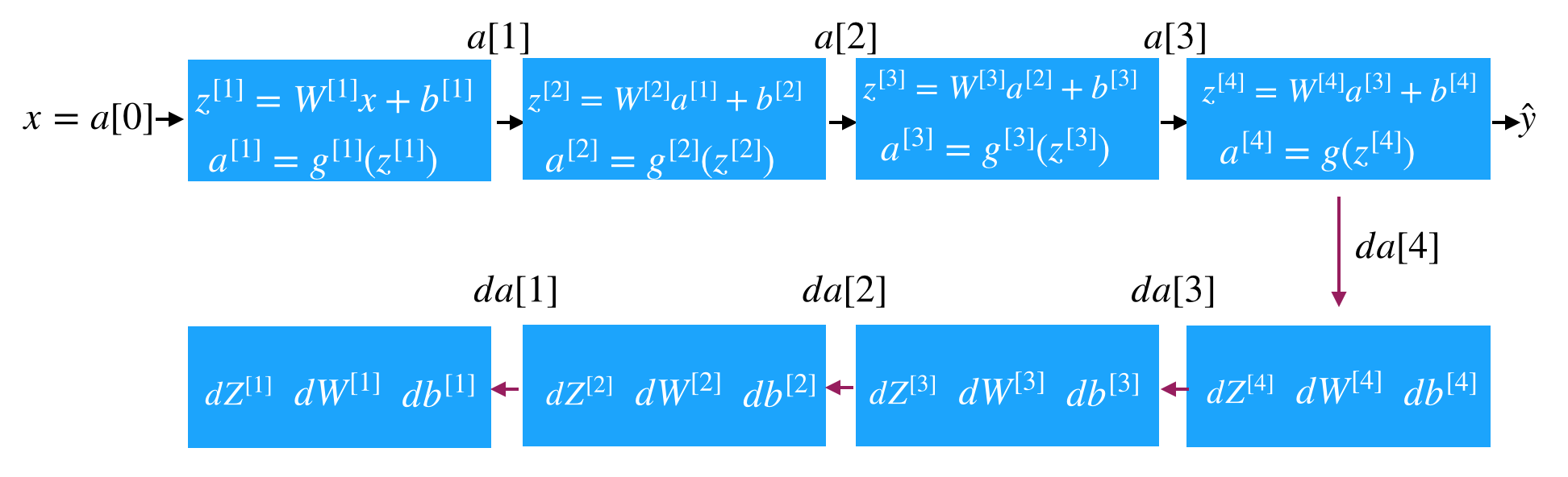
$$
\begin{split}
&dZ^{[L]} = \frac{\partial J}{\partial A^{[L]}} \cdot \frac{\partial A^{[L]}}{\partial Z^{[L]}} = dA^{[L]} \cdot g^{[L]'}(Z^{[L]}) \\
&dW^{[L]} = \frac{\partial J}{\partial Z^{[L]}} \cdot \frac{\partial Z^{[L]}}{\partial W^{[L]}} = \frac{1}{m}dZ^{[L]}A^{[L-1]T} \\
&db^{[L]} = \frac{1}{m}np.sum(dZ^{[L]}, axis=1) \\
&dA^{[L]} = W^{[L+1]T}dZ^{[L+1]}
\end{split}
$$
4.4 参数和超参数
参数(Parameters):在训练过程中希望模型学习到的信息,模型自己调整的参数
- 权重W通常使用随机初始化,避免对称性,$randn*0.01$
- 对称性:如果所有的神经元都具有相同的权重,那么在反向传播过程中,所有的神经元都会学习到相同的特征
- 乘系数0.01:使用Sigmoid函数或者tanH函数作为激活函数时,W比较小,则Z=WX+b所得的值趋近于0,梯度较大,能够提高算法的更新速度;ReLU函数则没有这个问题
- 偏置b没有对称性问题,通常初始化为0
超参数(Hyper parameters):通过人的经验判断、手动调整的网络信息,会影响最终的参数
- 典型的超参数:学习速率$\alpha$、迭代次数$N$、隐藏层数$L$、每层神经元数$n_i$、激活函数$g^{[i]}()$的选择
- 开发新应用时,很难预先准确知道最佳的超参数,需要通过不同的尝试和调整来找到最佳的超参数
五、多分类与Softmax回归
5.1 Softmax回归
对于多分类问题,种类个数C,则输出层的神经元个数必须为C,每个神经元的输出依次对应为每个类别的概率。
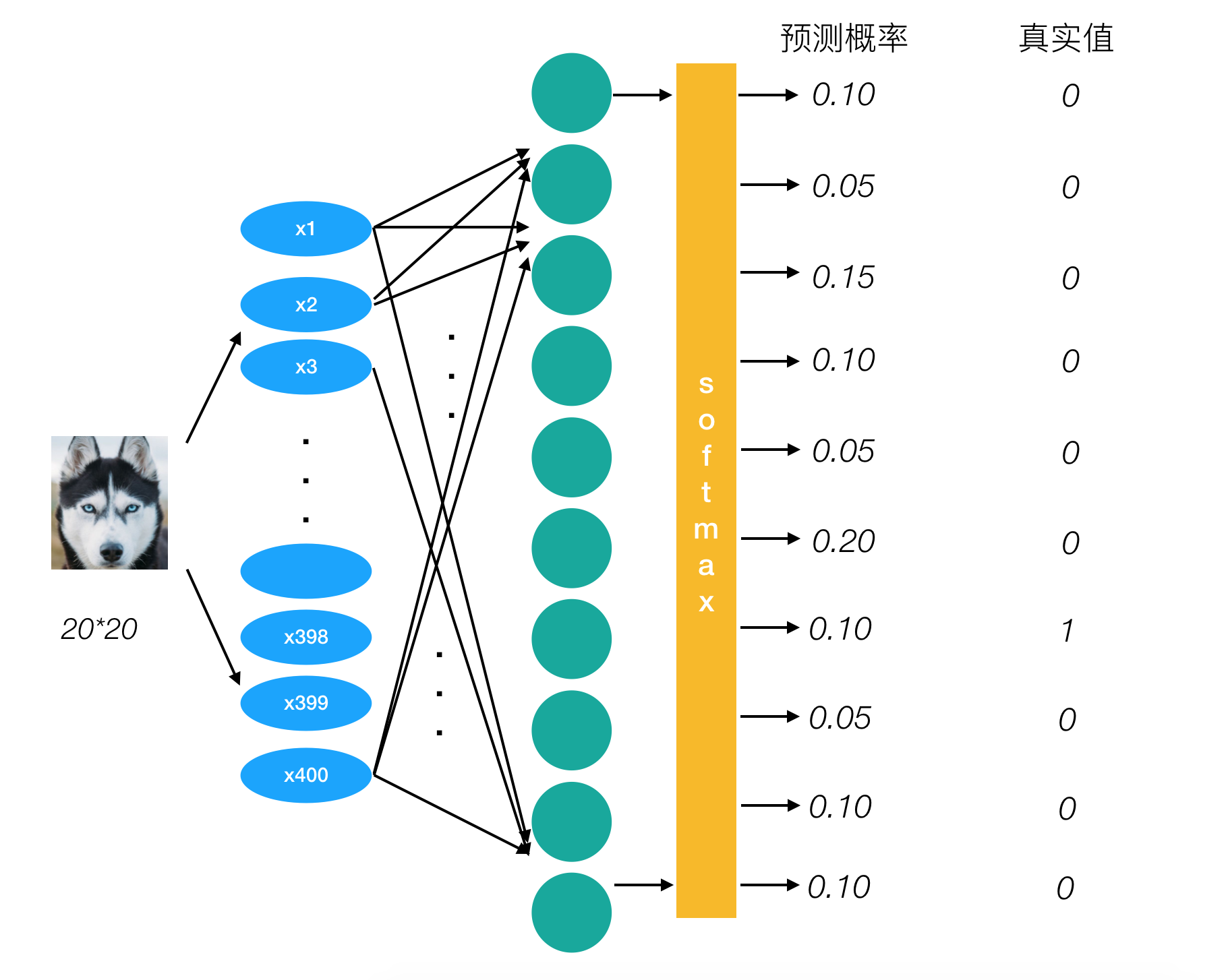
输出层:$Z^{[L]}=W^{[L]}A^{[L-1]}+b^{[L]}$$
Softmax公式:$a_i^{[L]} = \dfrac{e^{Z_i^{[L]}}}{\sum\limits_{j=1}^{C}e^{Z_j^{[L]}}}$,满足$\sum\limits_{i=1}^{C}a_i^{[L]}=1$
理解:$e^{z_i}$的占比
5.2 交叉熵损失与One-hot编码
对于Softmax回归,使用交叉熵损失(Cross Entropy Loss)函数:
$$
L(\hat{y},y)=-\sum\limits_{i=1}^{C}y_i\log(\hat{y}_i)
$$
$C=2$时,即对应逻辑回归的对数损失函数$L(\hat{y},y)=-(y\log(\hat{y})+(1-y)\log(1-\hat{y}))$
one-hot编码(独热编码):将标签转换为向量,只有一个元素为1,其他元素为0。
以图2.1.1为例,$y=7$,则one-hot编码对应为$y=[0,0,0,0,0,0,0,1,0,0]$。
由于除了正确类别外,其他类别$y_i=0$,因此可以简单计算交叉熵:$L(\hat{y},y)=-1\times\log(0.10)$
这一项的预测值越接近1,交叉熵越接近0,模型效果越好