defk_means(data, k=3, max_iter=100): """K-means 聚类算法 Args: data: 数据集,list[element],element是一个list[float] k: 聚类数 max_iter: 最大迭代次数 """ # 初始化聚类中心 centers = random.sample(data, k) # 初始化聚类结果 clusters = [[] for _ inrange(k)] # 迭代聚类 foriterinrange(max_iter): # 分配数据到最近的聚类中心 for element in data: # 对于每个数据 min_dist = float('inf') # 最小距离 min_idx = -1# 最近聚类 for i, center inenumerate(centers): dist = sum((x-y)**2for x, y inzip(element, center)) # 计算距离 if dist < min_dist: min_dist = dist min_idx = i clusters[min_idx].append(element) # 更新聚类中心 new_centers = [None] * k for i, cluster inenumerate(clusters): new_centers[i] = [sum(x)/len(cluster) for x inzip(*cluster)] # 判断是否收敛:中心点是否变化小于eps eps = 1e-6 fl = all((sum((x-y)**2for x, y inzip(a, b)) < eps) for a, b inzip(centers, new_centers)) if fl oriter == max_iter-1: break centers = new_centers clusters = [[] for _ inrange(k)] return clusters
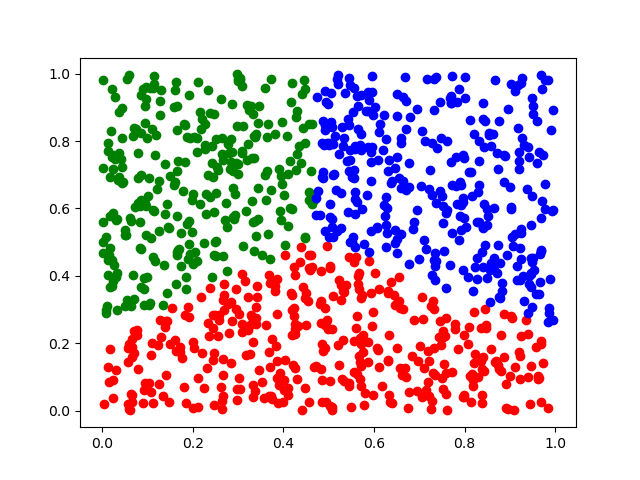
# 测试 data = [[random.random() for _ inrange(2)] for _ inrange(1000)] clusters = k_means(data, 3)
# 结果可视化 import matplotlib.pyplot as plt colors = ['r', 'g', 'b', 'y', 'c', 'm'] for i, cluster inenumerate(clusters): for element in cluster: plt.scatter(element[0], element[1], c=colors[i]) plt.show()
# 选择第一个聚类中心 centers = [random.choice(data)] # 选择其他聚类中心 for _ inrange(k-1): dists = [min(sum((x-y)**2for x, y inzip(element, center)) for center in centers) for element in data] probs = [dist**2/sum(dists) for dist in dists] centers.append(random.choices(data, probs)[0])